
机制(MT)已经走了很长一段路。从基于早期规则的系统到神经网络的出现,该领域见证了巨大的发展。十多年来,Unmabel一直处于这一发展的最前沿,因为它受益于诸如质量估算(QE)等最新技术,以提高翻译和流利度的准确性。
但是,尽管取得了所有进展,传统的MT模型仍面临着巨大的挑战。他们经常难以理解背景,处理复杂的语言结构或适应各个领域。虽然适应该领域是部分解决方案,但培训术语的个人模型,优雅的证据和声音音调很昂贵,并且总是无法进行当前的翻译动态。不仅如此,在许多情况下,自动翻译仍然需要人类进行审查和纠正。
这是人工智能和大型语言模型准备改变一大步的地方。由于其广泛的知识及其理解和产生类似人类的文本的能力,它们是解决自然语言领域的一场革命,具有理解背景,处理细微差别的能力,甚至以显着凝聚力进行多种语言对话。现在,我们希望在Umbasel中将这项技术的强度转换为翻译。
在此博客文章中,您将了解:
- 数据在完善和培训大语言模型中的主要作用
- 碎片(增强的回收的增强)如何适应和分配
- Undabel规范数据隐私政策制定LLM
- LLM的结果将由国际特赦组织领导
- 如何支付塔洛姆的混合以及对翻译,愿景和性能效率的巨大提高的质量欣赏
这是欧洲项目(统一复制和翻译扩展现实的统一复制和翻译)的结果,该项目由欧盟的研究与创新计划根据授予协议编号101070631资助。有关更多信息,请访问:https://he-tuter.eu/ https://he-tuter.eu/
数据中的详细信息
随着塔拉姆的推出,专门设计用于翻译和相关任务的领先语言LLM,Unclabel处于这种巨大转型的最前沿,并基于人工智能的多年研究和开发,并为新时代的翻译人工智能铺平了道路。
皇家版本的塔楼允许客户通过整个翻译的功能(可用的Towlllm的开源版本的开源版本)取消出色翻译的质量和性能的形成,因为它是在观众可用的两个数据上构建的,此外还有不贴有标记的翻译数据。
让我们浏览如何设计和建立从塔拉姆的重复。塔LIND是不同的,因为它是设计的多语言。我们已经使用我们的LLM质量评估Compkiwi精心赞助和过滤的高质量多语言数据的广泛数据训练了它。尽管众所周知的大型语言模型(例如GPT-4O)是对来自不同语言的数据的培训,但根据混合和未确认的质量,这些数据是污染训练以及该模型的性能的定义。塔洛姆(Lowlllm)受益于培训,测试和改进此最佳质量数据,这意味着它在理解文本和以不同的语言中生产它方面表现出色。
我们使用执行特定翻译任务的公式迈出了这一一步,其中一个是翻译,但也是源校正,识别命名实体,邮政编辑和其他简化翻译过程,减少错误并提高一致性的编辑。为了执行这些指定的任务,我们创建了一个称为TowerBlocks的单独的专业数据集,该数据集由每对公共和内部数据语言中的索赔和示例组成。这种广泛的数据促进将塔洛姆精确的压力超出了简单的翻译步骤,并支持整个翻译过程。
现在,我们谈到了培训,让我们谈谈持续改进。有时,被称为贝壳或少数或抹布(增强的检索生成)的lothlm被要求在实际时间适应客户的特殊需求,从而使其成为不断变化的需求和公司面临的公司条件的强大工具。在导航期间,适应性被用作以前的高质量翻译,作为与特定区域,模式,新术语等连续适应的参考点,仅使用很少的示例,以及翻译后的几分钟。这种极为快速的培训仅受益于高质量的输入,使客户可以以低成本取消适应不断变化的条件,并且由于它是自动的。
在当前版本中,塔拉姆引线:
- 自动翻译 18对语言丈夫的优点,确保了多种语言的准确和流利的翻译。
- 实体的名称 要定位名称,标准和符号(例如货币,权重,网站和品牌),并实现与文化相关的翻译。
- 源校正 要摆脱语法和拼写错误,请提高翻译内容的质量和内容。
- 解放后的机器 这会根据人工智能的质量评估自动改善翻译,从而减少了对手动干预的需求。
在接下来的几个月中,塔LM将充满更多的语言对和更多的翻译任务,以增加翻译过程的增强和改进。
数据隐私,不支持
达到这种绩效水平,需要将公共数据和所有权数据混合在一起,通过这种方式,通过我们的隐私和安全性衡量标准,塔洛尔姆得到了支持和不断发布。培训人工智能模型需要大量数据并不是一个秘密,但这并不意味着它不应该安全。我们已经看到许多人工智能公司提供了如何处理和使用敏感数据的不清楚或不理解释。不在不受欢迎的情况下。我们致力于确保我们的客户数据始终是安全的。
通过经过久经考验的过程,我们在典型培训之前故意通过精确的协议隐藏敏感信息,这意味着没有特殊数据以形式形式。此外,我们可以遵循客户的需求,通过我们自己的橡皮擦技术清洁数据,从而使我们在出版塔拉在生产中发表塔拉时可以灵活地满足客户需求。
为什么llms在这里翻译以留在这里
在塔LM版本中,Uncabel在与GPT-4O的人工智能领域以及更传统的MT播放器(如Google and Deepl)中,Uncabel均超过了竞争模型。根据我们基于巨大的通用模型的构建方式,他们接受了已清算的最佳质量数据的培训,并且对丰富的索赔进行了指示,塔拉姆将以不是这些竞争对手的方式向客户解决这些问题。
这有很多意义。在大规模可用的大型语言模型的时代,机会是分配模型,而不是从零点构建模型。通过这种方式,诸如Unbabel之类的公司能够提供价值的AI产品,这些产品受益于深厚的环境理解和LLM,并将其转换为具体的特定问题。在最近的博客出版物上评论了GPT-4O版本,Sam al-Gmanan说:“我们开始开放时的最初概念是,我们将创建人工智能并使用它来为世界创造各种好处。相反,现在我们似乎将创建国际特赦组织,然后其他人将使用它来创造各种各样的惊人事物,我们都从中受益。 “有了塔洛姆,这就是Unberabel在翻译中所做的。
并非每个人都同意,正如某些人提到的那样,特定的神经MT仍将优先考虑为人工智能的主要翻译,但是我们的结果也是如此。
数字怎么说? 我们使用皇家客户的数据进行了一系列实验,该数据是通过14对语言,一种语言(英语 – 德语)以及多语言思维和理解任务进行翻译的。

图1:14对语言的翻译
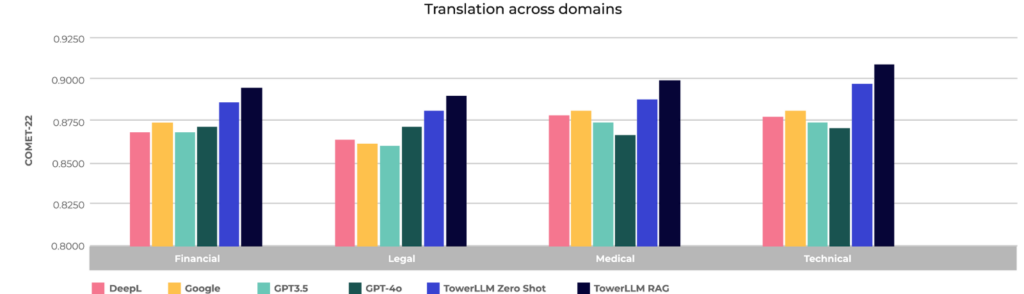
图2:通过德语英语的财务,法律,医学和技术领域的翻译
等级的差异很有用,因为彗星跟踪基于人类意识的翻译准确性。在语言对的经验中,Unclalbel平均比其他模型在0.4到1.4彗星22点之间,在田野实验中的1.8至2.6彗星22分之间,但这是什么意思?当塔洛姆(Lowlllm)从另一个模型中得分0.4点,人类倾向于同意塔拉姆(Tolllm)比其他73.0%的时间更好。同样,当塔拉姆2.6是有罪点时,人类同意塔拉姆是最好的96.2%。塔拉阴影显示了其他型号的这些显着而明显的质量改进。
通常,这些结果表明,塔拉姆在理解语言的细微差别,捕获预期的含义以及产生翻译不仅准确,而且很自然而流利。对于公司而言,这些功能被转化为巨大的好处,因为塔洛尔(Lowlll)减少了免费的文章编辑和手动审查的需求,这简化了翻译过程,这导致了更频繁的高质量多语言连接。
大赦国际运作的翻译未来
塔洛姆(Lowlllm)代表了代理翻译的演变中的一个巨大飞跃,并且随着基本技术的发展以及越来越准确的数据被收集并从中受益,我们希望能够看到绩效的提高。我们还希望替换塔洛(和其他LLM)的零件和更多的零件和更大的零件,这将使输出更加一致,并将人类审计师置于仅进行最重要的干预措施的地方,同时从更高级别指导翻译程序。
不仅以更好的自动翻译停止。 Unterbel质量估计技术的高级高级功能和质量使大型机构将更多内容转换为人工智能的翻译变得更加简单,更可靠。通过确定错误并确保高质量产出的能力,公司可以自信地扩大翻译工作,减少手动干预并获得更快的多语言内容市场。
通过利用高级语言模型的力量,并在自动翻译和质量估计方面具有无态度的经验,我们为多语言交流中的准确性,流利度和成本效益设定了新标准。
要了解有关塔拉姆的更多信息,以及如何将多语言通信转换为您的工作,请访问我们的预期页面并订阅我们的网络研讨会。您还可以在自己的界面上测试塔洛姆。





