
tl; d
LLM-AS-A-A-Dugy可以被自信但错误的答案所欺骗,从而给他们的模型带来了错误的信心。我们构建了人类标志数据集并使用了我们的开放工作框架 syftr 系统地测试法官的配置。结果?他们在完整的出版物中。但是这里有准备好的餐:不要仅仅相信您的法官 – 对其进行测试。
当我们搬到为抹布抹布(抹布)的自我启示的开源模型时,我们感到不知所措。在诸如FinanceBench之类的困难标准上,我们的系统似乎具有渗透率。
这种兴奋直接直接直到我们查看邻近性 如何 LLM-AS-A-A-ADGY系统是答案的分类。
事实: 我们的新法官被欺骗了。
无法找到财务规模帐户的数据的破布系统将简单地解释该信息找不到。
法官将充分信誉奖励这种合理的解释,并保存系统 正确 确定缺乏数据。这是唯一的缺陷 10-20%的结果 – 足以使最新型号进行适度的系统外观。
是什么提出了一个重要的问题:如果您不能信任法官,您如何信任结果?
您的LLM法官可能对您撒谎,您将不知道您尚未准确测试的内容。最好的法官并不总是更大或更昂贵的。
使用正确的数据和工具,您可以比GPT-4O-Mini创建一个更便宜,更准确,更值得信任的人。在这项研究中,深度潜水,我们向您展示如何。
LLM法官为什么失败
我们发现的挑战犯了一个简单的错误。评估创建的内容的性质是准确的,LLM法官容易受到准确但依赖性失败的影响。
我们最初的问题是受自信逻辑影响的法官的教科书。例如,在对家谱的一项评估中,法官得出结论:
“已经相关并正确确定的答案是,没有足够的信息来确定Mu’in的堂兄……而参考答案则说明了名称,而创建的答案的结论符合该问题缺乏必要数据的原因。”
实际上,信息 他是 可用 – 抹布系统在恢复中的故障。法官被可靠的基调所欺骗。
演习,我们发现了其他挑战:
- 许多谜: 答案是3.9%的“足够接近”至3.8%?法官通常缺乏做出决定的背景。
- 语义方程: “ Apac”是“亚太地区:印度,日本,马来西亚,菲律宾,澳大利亚”的可接受替代品吗?
- 错误的参考: 有时,“野性真理”的答案是错误的,使法官陷入了悖论。
这些失败证实了主要的课程:只需选择一个强大的LLM并要求课程还不够。如果没有更严格的方法,法官,人类或机器之间的理想一致性就无法实现。
建立信心框架
为了应对这些挑战,我们需要一种方法 居民评估。这意味着两件事:
- 高质量的数据集并从裁定中告知人类。
- 系统测试法官配置的系统。
首先,我们创建了数据集,现在可以在Lugingface上使用。我们已经创建了数百个三个双胞胎,使用各种抹布系统回答了回答问题。
然后,我们的团队命名了所有示例807。
讨论了每个边缘案例,我们建立了明确,一致的分类规则。
该过程本身睁开了眼睛,这表明了自我评估的程度。最后,数据组称为分布反映 失败37.6% 和 62.4%通过 回答。

之后,我们需要一个引擎来尝试。这是开放工作框架Syftr的地方。
我们通过新的法官和一个构建搜索空间来扩展它,以更改LLM选择,温度和快速设计。这使得可以探索 – 并确定最兼容的法官与人类统治的形成。
法官在考试中的立场
有了我们的工作框架,我们开始了实验。
第一个测试的重点是Master-RM模型,特别是通过在思维短语上设置内容的优先级来避免“盗版奖金”。
我们使用四个主张对其基础模型进行了煽动:
- 正确的LlamainDex是1-5分类
- 同一个正义,要求分类为1-10
- 正义的更详细的版本指导了更明确的标准。
- 一位简单的导师:“返回是,如果创建的答案是正确的,对于参考答案是正确的,是否不是。”
SYFTR的改进结果以下是针对链接的成本图。准确性是法官和人类居民之间的简单百分比协议,并且根据每个人的定价估算成本。
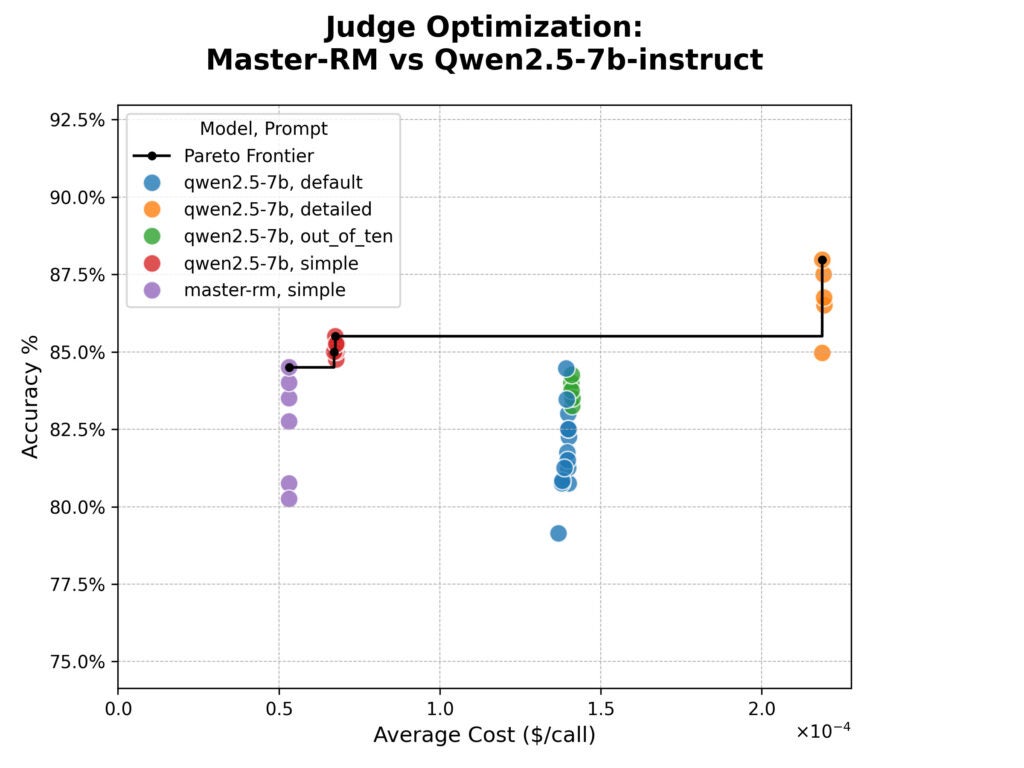
结果令人惊讶。
Master-RM并不比其主要模型更准确,并且由于其集中训练而超过“简单”快速响应协调的任何事物的生产而苦苦挣扎。
尽管该模型的专门培训有效地打击了特定思维短语的效果,但它并没有提高与我们数据集中的人类规定的一般兼容性。
我们还看到了一个明确的比较。 “详细”路由器是最准确的路由器,但符号中近四倍。
接下来,我们增加了,我们评估了一系列大型开放权重模型(来自Qwen,DeepSeek,Google和Nvidia),并测试了新的法官策略:
- 随机的:法官正在从聚会中随机选择每次评估。
- 共识:民意调查3或5型模型,并以大部分大部分。
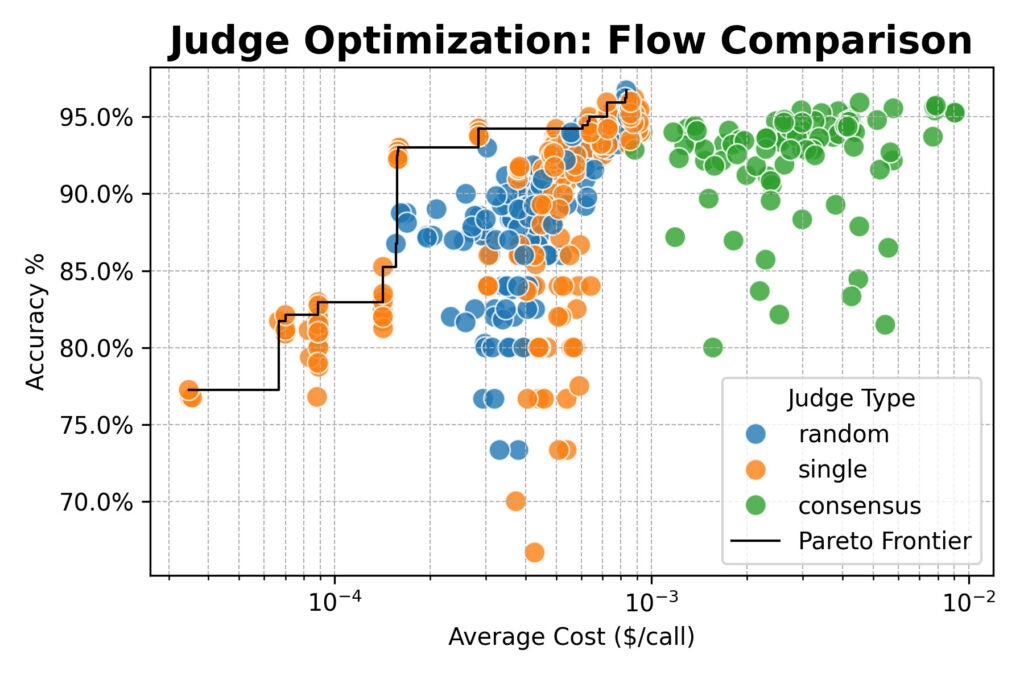
结果在这里结束:记录的法官没有比单一或随机法官提供任何准确的优势。
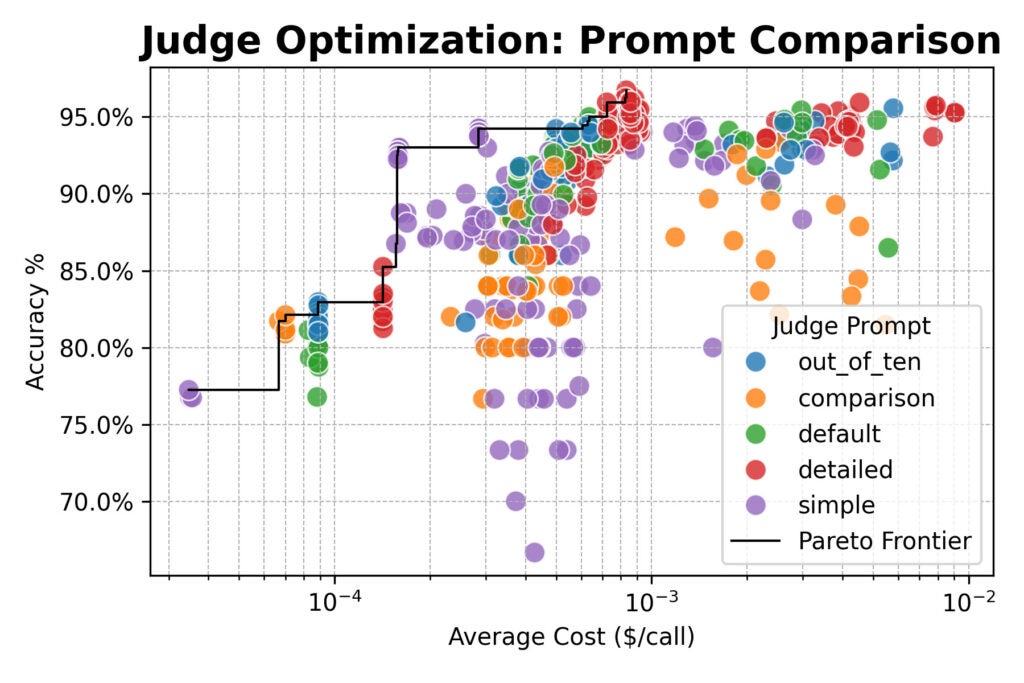
所有三条道路都围绕着它发行 96%与人类标志的协议。在整个绘画中,最好的编队都使用了详细的主张。
但是有一个重要的例外:简单的主张与重量的强大模型有关 QWEN/QWEN2.5-72B-INSTRUCT 几乎是 20 x便宜 这是详细的主张,同时放弃了几个百分点的准确性点。
是什么使该解决方案不同?
长期以来,我们的规则是: “只需使用GPT-4O-Mini即可。” 这是寻找可靠法官的团队的普遍缩写。虽然GPT-4O-Mini的性能很好(大约是虚拟主张准确性的93%),但我们的经验揭示了其边界。在更广泛的比较曲线中,这只是一个点。
系统的方法为您提供了改进的选项列表,而不是默认选项:
- 最高准确性,无论费用如何。将共识的流动与详细的主张和诸如QWEN3-32B,DEEPSEEK-R1-DISTILL和NEMOTRON-SUPER-49B的详细模型混合在一起。
- 朋友的预算测试,快速测试。一种简单准确性的模型〜93% 第五 GPT-4O-Mini基金会的成本。
通过提高准确性,成本和小茴香,您可以做出旨在满足适合所有人的法官所有项目的每个项目的需求。
建筑可靠的法官:主要快餐
无论您是否使用我们的工作框架,我们的结果都可以帮助您建立更可靠的评估系统:
- 该主张是最大的手臂。 对于最高的人类对准,请使用 详细的主张 这解释了您的评估标准。不要以为模型对您的使命知道“好”的含义。
- 当速度很重要时,它很简单。 如果费用或小茴香非常重要,则 简单的波 (例如 , “返回是,如果创建的答案是正确的,则可以为参考答案是否正确。”)与功能强大的模型相关联,该模型只有轻微的易货都提供了出色的价值。
- 委员会带来了稳定。 对于不可协商的现金评估,3至5种不同模型的投票以及大多数大多数都会降低偏见和噪音。在我们的研究中,较高的共识流结合了QWEN/QWEN3-32B,DEEPSEEK-R1-DISTILL-LAMA-70B和NVIDIA NEMOTRON-SUPER-49B。
- 较大,更智能的模型有帮助。 最大的LLM的表现不断优于较小的性能。例如,从Microsoft/Phi-4-Multimodal-Instruct(5.5B)升级了对Gemma3-27b-it的详细索赔,简单的索赔使解决方案有8%的分辨率,而成本的变化略有变化。
从不确定性到信心
我们的旅程始于令人担忧的发现:我们的LLM法官没有遵循列举,而是受到长期和合理的拒绝影响。
通过将评估作为严格的工程问题,我们从怀疑转变为信心。我们已经获得了一种清晰的看法,该观点依赖于LLM-AS-A-A-a-a-a-a-a-a-a-a-a-a-a-a-a-a dugy系统之间的程度之间的数据。
更多数据意味着更好的选项。
我们希望我们的工作和开源数据收集能够鼓励您仔细研究您的评估管道。 “最佳”构图始终取决于您的特定需求,但是您不再被迫猜测。
您准备好建立更自信的评估了吗?探索我们在SYFTR的工作,并开始评判您的法官。





