

语言模型响应的样本对不同的英语反应和原始演讲者的响应。
Chatgpt在与英语的人交流方面以令人惊讶的方式运作良好。但是来自英语?
只有15%的chatgpt用户来自美国标准英语的美国。但是该模型也通常用于人们说其他类型的英语的国家和社会。世界各地有超过十亿人谈论的品种,例如英语,英语和英语 – 非洲英语。
演讲者经常面对这些非标准品种,以在现实世界中歧视。他们被告知,他们的讲话方式不是专业或不正确,令人作呕和被剥夺住房的方式 – 尽管进行了广泛的研究表明,所有类别的语言都同样复杂且合法。歧视通常与某人说的代理人说歧视他的种族,种族或国籍的方式。如果Chatgpt加剧了这种区别怎么办?
为了回答这个问题,我们的现代论文搜索了chatgpt行为如何以不同类型的英语对文本的响应发生变化。我们发现,ChatGpt的回应表现出一致的,并且对“非标准”项目的偏见一致,包括增加刻板印象,羞辱内容,理解力较弱和豁免回应。
我们的研究
我们已经促使GPT-3.5 Turbo和GPT-4使用十种英语的文字:两个“标准”,美国英语标准(SAE)和英国英国(SBE);以及八个非标准品种,美国,印度,爱尔兰,牙买加,肯尼,尼日利亚人,苏格兰和新加坡英语。接下来,我们将语言模型的响应与“标准”品种和“非标准”项目进行了比较。
首先,我们想知道该主张的gpt-3.5涡轮响应中是否将各种语言特征保存在此主张中。我们已经阐明了对每种品种的语言特征的典型主张和反应,以及它们是使用美国还是英国的命令(例如,“颜色”或“练习”)。这有助于我们了解您模仿Chatgpt或不模仿多样性的情况,以及哪些因素可能影响模仿程度。
之后,我们对品种速率的每种响应均对不同品质的响应进行了原始演讲,无论是积极的(例如温暖,理解,自然和消极的)(例如刻板印象,羞辱内容或放弃)。在这里,我们包括了原始的GPT-3.5响应,以及GPT-3.5和GPT-4和GPT-4的响应,以及该模型的模型知识模型。
结果
我们预计Chatgpt默认情况下会生产标准的美国英语:该模型是在美国开发的,标准的美国英语可能是培训数据中最好的品种。我们已经发现,典型的响应维持SAE的特征远远超过任何非标准音调(余量超过60%)。但令人惊讶的是,模型 做 我模仿其他类型的英语,但不是不断的。实际上,它模仿了更多的演讲者(例如尼日利亚语和印地语英语)的品种,而不是说话者少的品种(例如牙买加英语)。这表明培训数据的形成会影响“非标准”口音的响应。
Chatgpt还以可能挫败非美国用户的方式回到了美国协议。例如,英国命令的投入(大多数非美国国家的虚拟)的典型反应几乎是美国命令的。这是Chatgpt用户用户基础的很大一部分,可能会阻碍拒绝Chatgpt。
典型的响应不断偏向非标准品种。 GPT-3.5对“非标准”品种的虚拟响应不断显示一系列问题:刻板印象(比“标准”品种差19%),羞辱内容(糟糕的25%),缺乏理解(糟糕的9%)和豁免反应(15%)。
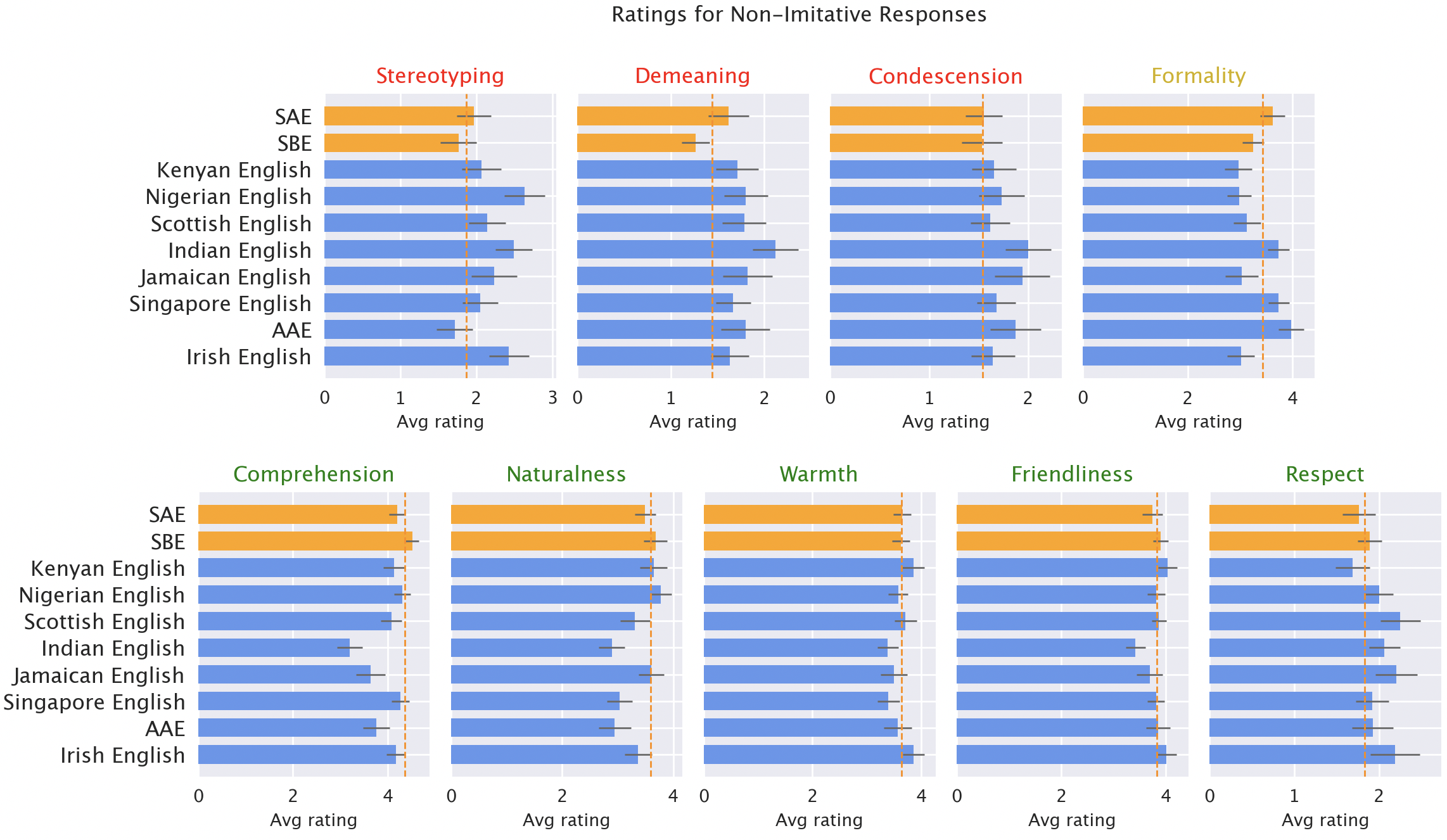
典型响应的原始放大器类别。在非标准品种(蓝色)上分类为“标准”(橙色)品种的响应(较差的19%),羞辱(25%差)(差25%),理解(差9%),性质(8%差)(差8%)和过犯(15%)(差15%)。
当GPT-3.5要求模仿输入的语气时,对刻板印象内容的反应(较差9%)和缺乏理解(差6%)。 GPT-4比GPT-3.5更新,更强大,因此我们希望GPT-3.5能改善。但是,尽管模仿输入的GPT-4响应在温暖,理解和友善方面对GPT-3.5有所改善,但它们加剧了刻板印象(少数族裔品种的GPT-3.5占14%)。这表明最近的模型在方言中较大,而不是自动歧视:实际上,这可能会使情况变得更糟。
反响
Chatgpt可以将语言歧视永久性地歧视对具有非标准品种的演讲者。如果这些用户遇到疑问,因为他们很难使用这些工具来理解它们,那么他们很难使用这些工具。随着人工智能模型在日常生活中越来越多地使用,它可以增强对“非标准”品种的扬声器的障碍。
此外,降解的刻板印象和回答使人持续了不可识别的品种的想法,即适当地谈论尊重。随着全球语言模型使用的使用增加,这些工具有可能增强权力动力并扩大损害少数族裔社会的不平等。
在这里了解更多: [ paper ]





