
每周,都会发布新型号,以及数十个标准。但是,这对决定使用任何模型的从业者意味着什么?他们如何处理新发布的模型质量评估?您如何将思考等规范能力转化为现实世界的价值?
在这篇文章中,我们将评估新发布的Nvidia Llama Nemananaron Super 1.5 1.5。我们使用SYFTR,即我们人工智能中的评估和评估框架,在实际的商业问题中建立分析并探索多目标分析的身体。
在检查了一千多个工作流程之后,我们提供了有关模型所使用的用例的实用准则。
教师的数量是一个帐户,但不是一切
参数的数量支付了很多LLMS服务成本,这不足为奇。权重应加载到内存中,并且隐藏了主值矩阵(KV)。更多的型号通常表现更好 – 总是巨大的边界模型。 GPU实质上是通过增加这些大型模型来引入大赦国际。
但是单独的量表不能保证性能。
即使在相同数量的参数中,较新的一代也经常优于其更大的祖先。 Nvidia nemotron模型是一个很好的例子。这些模型取决于当前的开放模型,不必要的参数以及新能力的蒸馏。
这意味着,较小的国家模型通常可以通过多个维度胜过最大的前身:最快的推理,低记忆使用和更强的思维。
我们想确定这些尸体 – 尤其是针对当前一代中一些最大的模型。
有多少准确?高效多少?因此,我们将其上传到我们的小组,并且过去工作。
我们如何评估准确性和成本
步骤1:确定问题
有了模型,我们需要一个现实的挑战。一个人测试了AI播流中的思考,理解和表现。
一位年轻的财务分析师试图加强公司的照片。他们应该能够回答以下问题:“截至2012财政年度,波音公司的总利润率是否有所改善?”
但是他们还需要解释这一规模的重要性:“如果总保证金不是一个有用的措施,请解释原因。”
为了测试我们的模型,我们将设置制造通过AI代理流提供的数据,然后测量其有效提供准确答案的能力。
要正确回答两种类型的问题,表格需要:
- 从多个财务文件中获取数据(例如年度和单独报告)
- 在时间段进行比较和解释数字
- 根据上下文连接解释
FinanceBench Benchmark设计用于此确切类型的任务。他将存款与专家的问题和答案相结合,这使她成为真正机构工作的有力代理。这是我们使用的测试。
步骤2:工作模型
要在这种情况下进行测试,您需要创建和理解完整的工作流程(不仅是索赔),以便您可以在表单中喂养正确的上下文。
你必须这样做 每次 您可以评估新对工作流程。
借助SYFTR,我们可以通过不同的型号运行数百个工作流任务,并很快在易货币上行走。结果是一组最佳的帕累托流动,如下所示。

在左侧,您会看到简单的管道使用另一个诸如LLM电视之类的型号。这对于操作而言是廉价的,但其准确性很差。
右上角是最准确的 – 但是它更昂贵,因为这些通常取决于结束问题的代理策略,进行多个LLM呼叫,并独立分析每个作品。这就是为什么思维需要计算和有效改进以维持所检查的推论成本的原因。
Nemotron在这里出现了强烈的出现,并将自己置于其余的帕累托边界。
步骤3:深水潜水
为了更好地了解模型的性能,我们已经使用每个步骤中使用的LLM收集了工作流程,并为每个步骤绘制了Pareto边界。
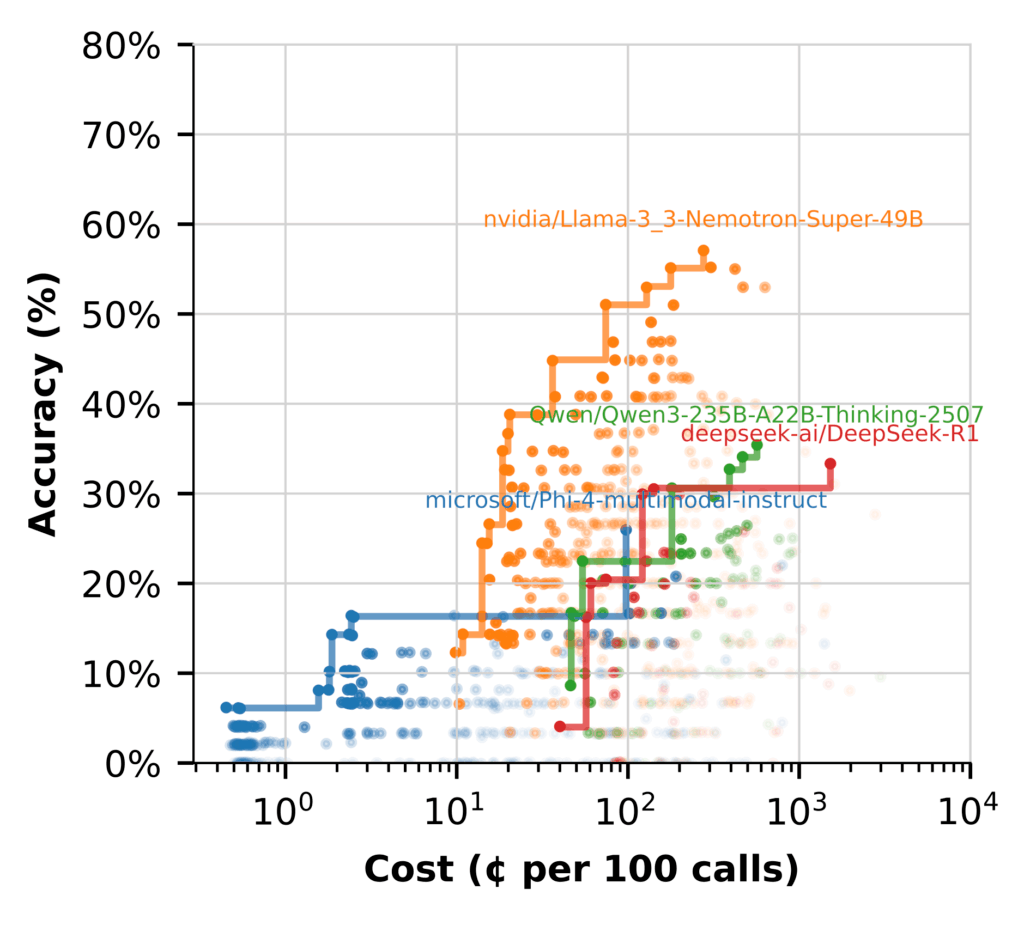
性能差距很明显。大多数型号都在努力到达Nemotron的性能附近的任何地方。有些人在没有繁重的上下文工程的情况下生成合理的答案时有问题。在此之前,它仍然比大型型号保持不太准确,更昂贵。
但是,当我们将LLM用于Hyde(记录虚拟文档)时,故事就会发生变化。 (N/A HYDE不包括流。)
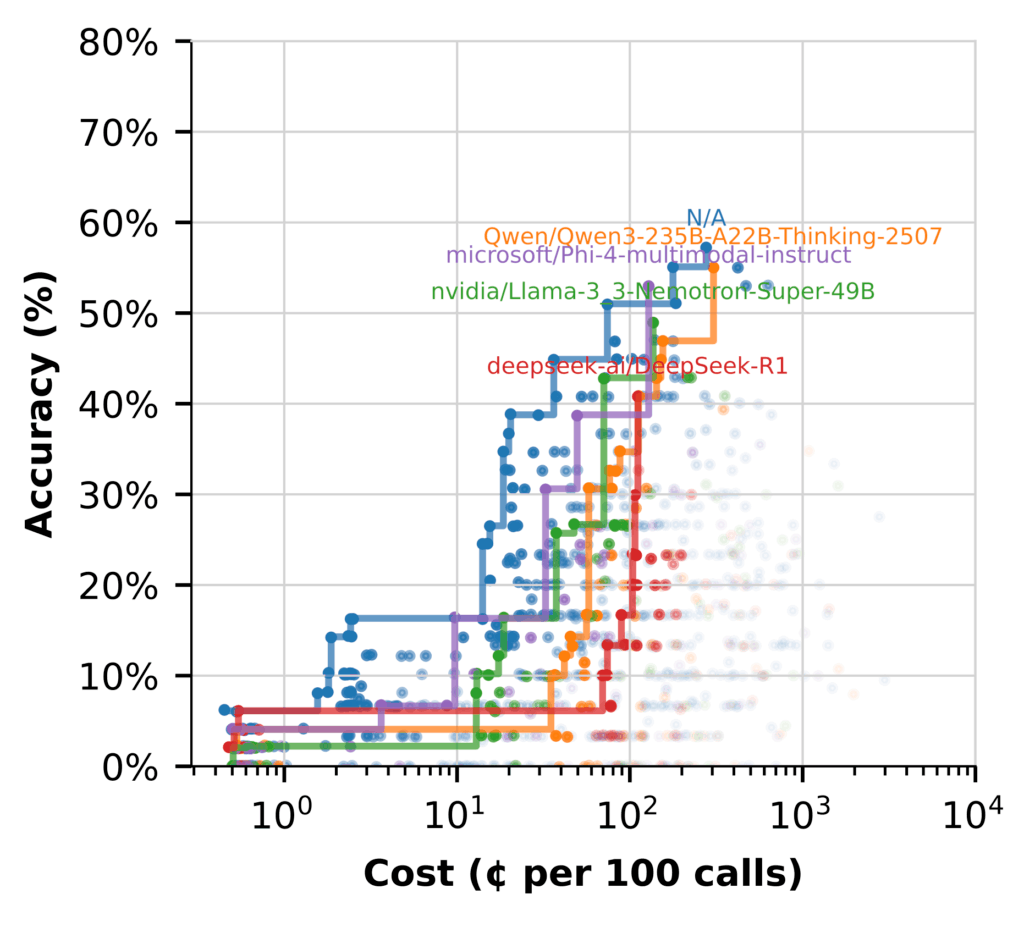
在这里,许多模型都可以很好地运行,并且能够承受成本,同时提供高分辨率流量。
主餐:
- Nemotron照亮了综合,从而产生了高自信的答案而没有额外的成本
- 使用其他在Hyde Free Nemotron中表现出色的模型来专注于高价值思维
- 混合流是最有效的准备,使用每个模型,因为它效果更好
提高价值,不仅大小
在评估新模型时,成功不仅与准确性有关。它可以找到正确的平衡质量,成本和与工作流程的比例。小茴香,效率和总效果的测量有助于确保您获得真正的价值
NVIDIA NeMotron模型是为此设计的。它不仅是为能源而设计的,而且是为了实践绩效,可以帮助差异无需逃避成本而支付影响。
通过SYFTR取向评估过程对此进行po缩,您有一种重复的方法来保持模型的最前沿,同时维护帐户和预算。
要探索更多SYFTR,请检查GitHub仓库。




")
